Michael Chungkun Chen
Project 1 Markov Chain Simulation
The problem statement is as follows:
You will have to simulate
an M/M/1 queuing system. Customers (or jobs) arrive into the queue to be serviced
(like in a bank), wait for their turn to be serviced and upon service leave the
queue forever. In M/M/1, the two M's stand for Memoryless signifying that the
interarrival times as well as the service times for the queue are exponentially
distributed. The 1 signifies that there is only one server serving the
customers.
In the first simulation, the arrival rate was 7 customers (jobs) per second, and the service time is 0.1 seconds. The simulation lasted for 100 seconds. In our system, we took the meaning of having a queue length of 1 to mean the server is serving 1 person with a queue of 0, and a queue length of 2 would mean the server is serving 1 and the queue contains 1. The following statistics was generated during the simulation:
|
Var |
Minimum |
Maximum |
Average |
Description |
|
Q |
0 |
8 |
2.212679 |
Queue
Length |
|
X |
0.000006 |
0.559787 |
0.091247 |
Service
Time |
|
W |
0 |
1.018829 |
0.193709 |
Wait Time |
|
S |
0.009264 |
1.224997 |
0.284957 |
Time in
System |
|
|
|
|
|
|
|
TAQL |
1.632542 |
Time
Averaged Queue Length |
|
|
|
Rho |
0.68531 |
Utilization
factor |
|
|
As we can see the Average service time is 0.091 seconds during the simulation, this value is near our specified 0.1-second theoretical parameter. We notice that with the utilization factor is at 0.68531, this factor is near our expected value of 0.7 since the arrival rate is 7 customers per seconds, and the service rate is 10 customers per second or 0.1 seconds per customer. We notice that the average queue length differs from the Time Averaged Queue Length quite a bit and is statistically different. This is due to the fact that the Time averaged one is averaged over time, and the average queue length is averaged over the arrival of jobs. We also take notice that the average queue length multiplied by the average service time is roughly equal to the average wait time. This would make sense since the wait time is basically how long this customer has to wait before the customers in front of it is done. As we can see the maximum queue length reaches 8, so even with the server being under utilized (Rho < 1) the queue can still reach 8. We also note that the queue length is not zero in any of the measures, even though the server is underutilized. This maybe due to the fact that at any moment a few customers may come in one after another, but when we have no customers, the next event must be a customer arrival. So the times when the server is idle will be very short, so most the time it is serving. So the queue is either one or two long more times than when it was 0 long. Causing the result we see with the average queue length and time averaged queue length.
Next we take a look at the plot of the Time Averaged Queue Length viewed at the arrival of each customer.
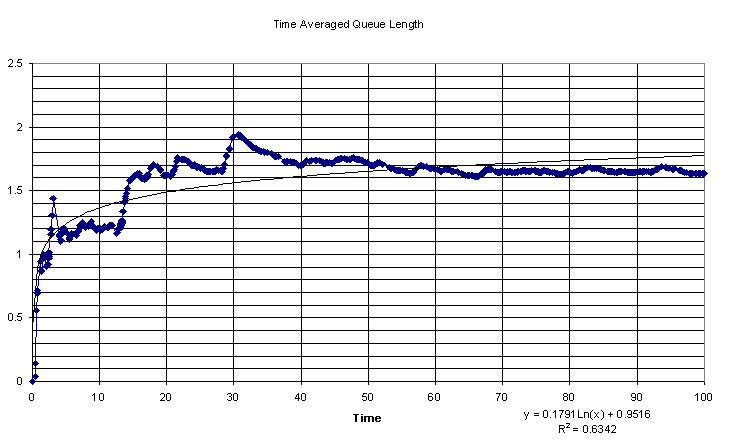
As we can see the time averaged queue length displays a logarithmic trend. This reinforces our assertion that the arrival and departure rates are exponential. As we continue the simulation to infinity, we notice that the Time Averaged Queue Length approaches a value near 1.63. We also notice that the trend becomes more stable as the simulation grows longer. This is due to the fact that the weight of the earlier data increases with time, so each new value would affect the Time Averaged Queue Length less and less. There are some large fluctuations in the beginning of the graph, which can be attributed to the nature of random variables. We now take a look at the Server Utilization plotted against time viewed at each job arrival.
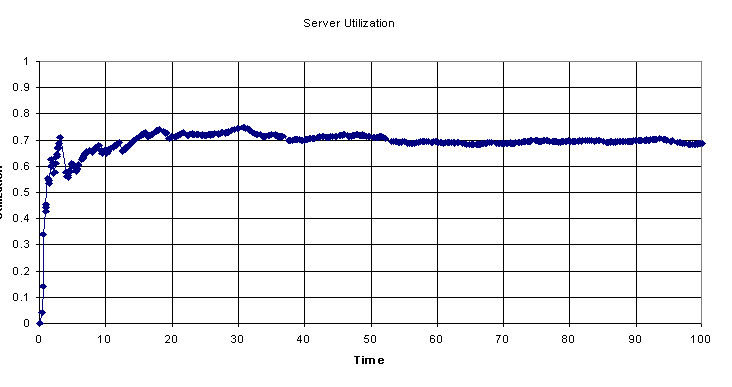
We notice that within 10 seconds the server utilization rate reaches a steady value. This graph shows that the server will be servicing customers 70% of the time, and 30% of the time it would be waiting for customers to arrive. Since the server rate is 10 customers per second, and the customer arrival rate is 7 per second, we would expect the server to be free about 30% of the time, and be busy for 70% of the time.
Next we change the arrival rate to 7.5 customers per second and keep our service rate the same at 0.1 seconds per customer. We obtain the following statistics:
|
Var |
Minimum |
Maximum |
Average |
Description |
|
Q |
0 |
12 |
2.945591 |
Queue
Length |
|
X |
0.000281 |
0.722406 |
0.099781 |
Service
Time |
|
W |
0 |
1.136652 |
0.280694 |
Wait Time |
|
S |
0.007472 |
1.327665 |
0.380475 |
Time in
System |
|
|
|
|
|
|
|
TAQL |
2.2421 |
Time
Averaged Queue Length |
||
|
Rho |
0.744203 |
Utilization
factor |
|
|
With a 7.1428% increase in our customer arrival rate, our maximum queue length jumped from 8 to 12, a 50% increase, of course our average queue length increased by 31%, our time averaged queue length increased by 37%. We notice that our average service time remains the same close to 0.1, which is our parameter that we specified. And our utilization factor increased to 0.744, which is close to what we expected: 0.75, our ratio of arrival rate to departure rate. Our average wait time meets our expectation, from our average queue length multiplied by the average service time. So with a small increase (7%) in our customer arrival rate, our latency increases (~30%). Next we look at the time averaged queue length of this system.
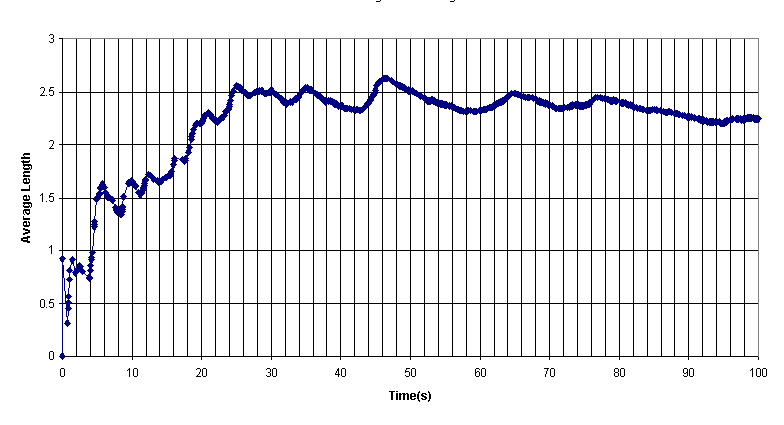
We notice that this graph is more fluctuating than the graph from the first
simulation. This is probably due to
randomness. We notice that all the
points are relatively close together within a short span of time, this would be
a property from time averaging the data.
There are crests and troughs in the graph, and this would mean that the
system periodically receives many customers, and then have a period where they
can finish servicing the customers already in the queue. Since the system is memoryless, whenever an
event, like customer arrival or departure happens, the next event occurs does
not account for the time already passed.
Next we look at the server utilization graph.
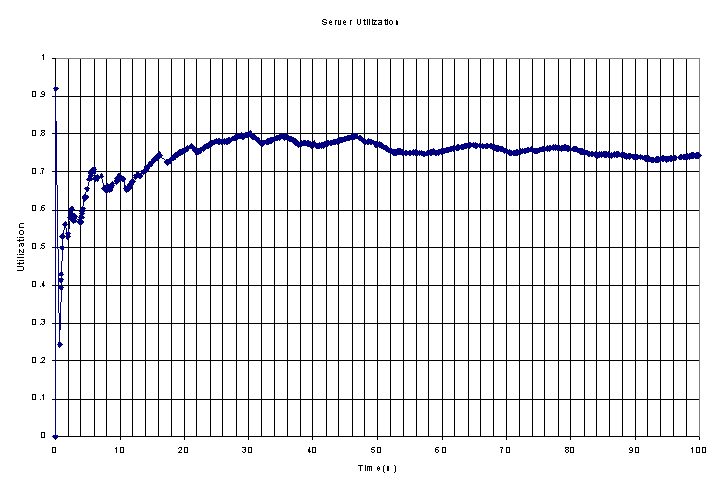
We can see that the server is utilized about 75% of the time as expected from our arrival and departure rates. We also see that in the very beginning the system is utilized over 90% of the time for a brief moment. This is possible if at the beginning we receive a job really early, and it runs 9 times longer than the idle time of the server before it departs.
Next we ran a simulation based on a customer arrival rate of 10 customers per second, which is equal to our service rate, which we kept at 0.1 seconds per customer. Before seeing the statistics we would expect that since the arrival rate equals the depart rate, there would be a 100% utilization rate, and no queues since as a customer arrive, another one leaves. The following is the statistics generated.
|
Var |
Minimum |
Maximum |
Average |
Description |
|
Q |
0 |
40 |
12.79634 |
Queue
Length |
|
X |
0.000024 |
0.784932 |
0.101505 |
Service
Time |
|
W |
0 |
3.61328 |
1.270326 |
Wait Time |
|
S |
0.003167 |
3.736954 |
1.371831 |
Time in
System |
|
|
|
|
|
|
|
TAQL |
12.81292 |
Time
Averaged Queue Length |
||
|
Rho |
0.948476 |
Utilization
factor |
|
|
We immediately notice that the queue length reaches a maximum of 40 and has an average of 12.79. This result diverges from expectation. The average service time is still the same around 0.10, and the wait time is still roughly equal to the average queue length multiplied by the service time. We will examine the Time Averaged Queue Length graph before we further comment on these results.
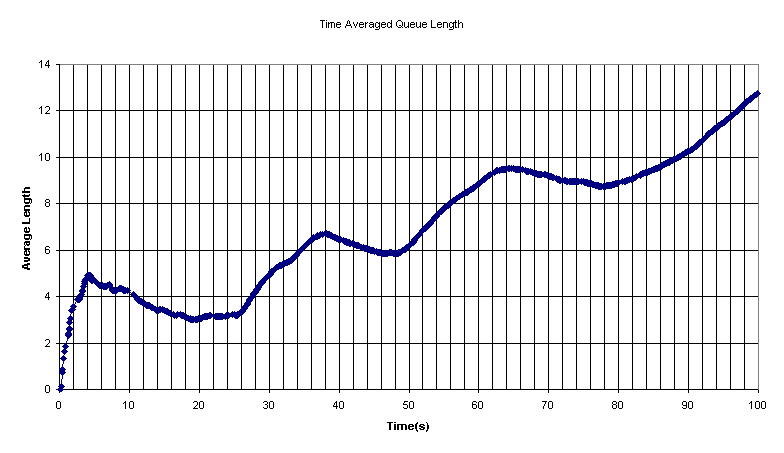
As we can see the time averaged queue length increases and increase. There are times where the length decreases a little but then it begins to increase again. So from this we guess that the queue length would probably keep growing, as time passes. But other than the unexplained general increase in average length, there is no trend. Since the service rate and arrival rate are equal, it is equally likely that at any point we increase or decrease the queue length. So we should expect a very random set of points. The reason why our points form a smooth line is because these values are time averaged.
Next we take a look at the server utilization for this simulation.
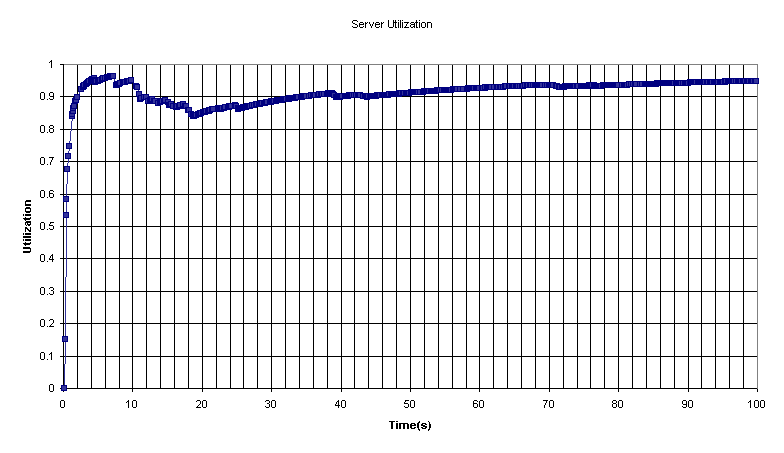
As this graph shows the server is utilized over 94.8% of the time on average. We expect an 100% utilization since the arrival rate is equal to the service rate, but one thing we must note is that when you work with a probabilistic system, there may be times when there are 10 arrivals in the first tenth of a second and 0 arrivals in the next nine tenths of a second giving us 10 arrival each second. So the rates are not absolute. We can only say that on average there are 10 arrivals per second. So the system may enter a state where we finish servicing the last customer and we wait for another to arrive. This would increase our idle time. And that seems to be what happened between 10 and 20 seconds. The rest of the time the system utilization increases.
In conclusion we can say that if we want to increase our server utilization we would introduce a lag time, which would increase our wait time, and time in the system. If we wanted to decrease our wait time, then we must decrease our server utilization. It is impossible to both increase server utilization and decrease wait time of the system. Queues will form even when our arrival rate is lower than the servicing rate. Unless the arrival rate and server rate is non-random, then it would either need no queue, or need an infinite queue or use a queue of set size. So in a system with costly queue’s and server speed is cheap, we would aim for a low server utilization to minimize the costs yet satisfy functionality, and vice versa. But we must maintain a server rate above the arrival rate or our queues become infinite.
|
|
||
|
Home | About Me | Text Depository | Future Enhancements | Guest Book | Links
All Rights Reserved. |